


11 Oct Indexer automatiquement vos vidéos avec IsyTaG®
La prolifération récente des vidéos constitue un défi majeur pour l’indexation documentaire. Sur un tel média, l’utilisation de méthodes d’indexation automatique devient incontournable. La transcription automatique de la bande audio offre de ce point de vue une source d’information remarquable. IsyTaG®, notre solution de tagging de vidéos, embarque un moteur de transcription fiable et innovant.
La multiplication des smartphones a fait de la vidéo un média incontournable : chaque seconde, 5 heures de vidéos sont uploadées sur YouTube ; en 2019, les vidéos représenteront 80 % du trafic de données sur Internet (https://www.cisco.com/c/en/us/solutions/collateral/service-provider/visual-networking-index-vni/complete-white-paper-c11-481360.html) ; dans de telles conditions, le visionnage par une seule personne de l’ensemble des vidéos qui transitent en un mois sur Internet prendrait 5 millions d’années !
Pour ne pas être noyées dans la masse et être rapidement retrouvées, les vidéos doivent être d’abord indexées. Sur de tels volumes, il n’est évidemment plus question d’envisager une indexation purement manuelle : à la différence d’un média comme l’image, dont le déploiement dans l’espace permet une appréhension globale et rapide, le flux vidéo nécessite le temps du visionnage et se révèle coûteux à indexer finement. L’indexation doit alors être secondée par des outils informatiques d’analyse automatique.
Les outils d’analyse automatique du contenu des vidéos peuvent s’appuyer soit sur l’image, et relever de la « vision par ordinateur » (computer vision) ; soit sur la bande audio, principalement sur les contenus parlés, et relever alors du « traitement automatique de la parole » (speech processing).
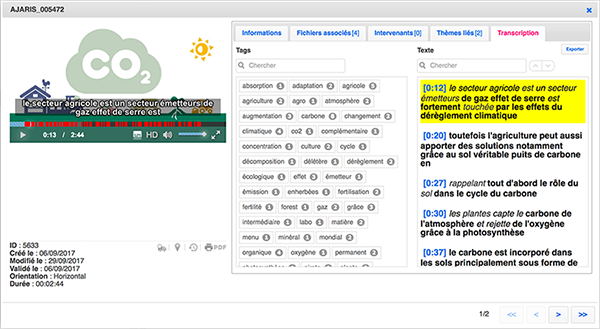
Exemple de sous-titrage automatique avec notre plateforme IsyTaG
Dans le cas d’une analyse par la bande audio, une phase préalable de transcription automatique du contenu parlé est nécessaire, en amont de la phase d’indexation proprement dite. La transcription automatique de la parole, dont les premiers balbutiements remontent aux années 1950, est désormais une technologie éprouvée : là où les premiers systèmes n’étaient capables que de reconnaître un nombre très limité de mots prononcés distinctement et séparément les uns des autres, les systèmes modernes sont capables de reconnaître dans un flux continu de parole spontanée près de 70 000 mots.
Les systèmes modernes de transcription reposent sur des algorithmes d’apprentissage automatique (machine learning), qui permettent à l’ordinateur d’apprendre à exécuter une tâche : on fournit à la machine des exemples variés de documents audio avec en regard la transcription faite par un humain (un « annotateur »), et elle apprend « seule » à associer les fréquences du signal sonore aux différents phonèmes (voyelles et consonnes) qui constituent les mots. Face à de nouveaux documents audio, elle sera alors capable de reconnaître les phonèmes qu’elle a appris et de proposer une transcription complète.
Néanmoins, la méthodologie de l’apprentissage automatique reste très dépendante des exemples sur lesquels la machine s’est « entraînée ». S’ils sont trop particuliers (accent standard, absence de bruit parasite…), la machine échouera à transcrire des documents enregistrés dans des conditions différentes (accent régional, musique de fond, contexte terminologique spécifique…). Pour être robustes à la variabilité acoustique, ces systèmes nécessitent des volumes considérables de données variées (habituellement plusieurs centaines d’heures d’enregistrements transcrits). L’apprentissage par réseaux de neurones profonds (deep learning) a récemment permis aux systèmes de transcription automatique de mieux résister à cette variabilité du signal audio, au point que cette technologique est devenue suffisamment performante pour être par exemple embarquée sur la plupart des terminaux mobiles.
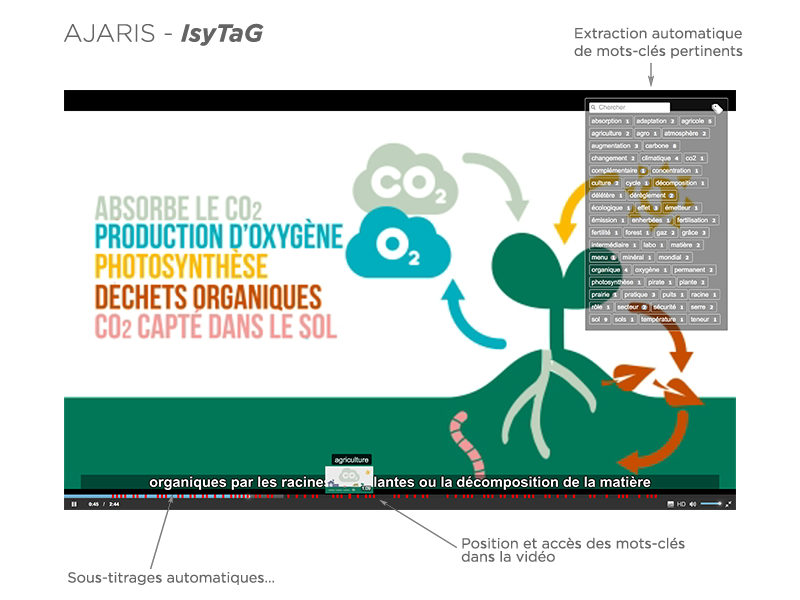
Notre système de transcription automatique, développé en partenariat avec de prestigieux laboratoires de recherche et en lien constant avec les besoins métiers de nos clients, constitue la première brique d’IsyTaG®, notre solution complète d’indexation des vidéos par la source audio. N’hésitez pas à nous contacter pour plus d’informations.
Vous avez des questions ? N’hésitez pas !
