



26 Juin Du DAM dopé au deep learning
Il travaille dans l’ombre et il est pourtant notre fierté. De qui s’agit-il ? De notre département R&D bien sûr. C’est en effet grâce à lui que notre logiciel Ajaris gagne chaque jour en fonctionnalités et en performances. L’occasion de vous le présenter.
Notre département innovation est piloté par Xavier Bost qui est arrivé chez nous en décembre 2016. Il est entouré de deux doctorants :
- Lucas Pascal, rattaché à Eurecom (école d’ingénieurs basée à Sophia Antipolis) qui travaille sur le deep learning appliqué à la reconnaissance et à la catégorisation des images fixes et des vidéos.
- Titouan Parcollet, rattaché pour sa part au Laboratoire Informatique d’Avignon (LIA), qui, après un master en alternance chez Atos, a démarré l’an dernier une thèse sur l’utilisation des quaternions dans les réseaux de neurones. Rares sont ceux qui travaillent sur le sujet. Son terrain de jeu : l’indexation automatique de l’audio et les dernières technologies de deep learning.

De Platon aux réseaux neuronaux
 Xavier Bost a d’ailleurs un parcours atypique. Âgé de 45 ans, notre homme a d’abord enseigné la philosophie pendant 15 ans dans le secondaire. “Un travail de DEA sur Platon en 2002 m’a donné l’occasion d’apprendre le grec ancien. Je me suis alors intéressé aux langues, plus particulièrement aux parentés entre langues, explique-t-il. Et comme il y a des méthodes assez algorithmiques qui sont utilisées dans ce domaine, la linguistique m’a conduit assez naturellement de la philosophie vers l’informatique”. Xavier a donc repris des études d’informatique, ce qui l’a amené à faire une thèse de doctorat au sein du LIA d’Avignon, un laboratoire en pointe sur le traitement automatique du langage et de la parole. Sujet de cette thèse : le résumé automatique de vidéos. L’idée étant de pouvoir soumettre une vidéo au logiciel, qu’il soit capable de repérer ses points forts et ses passages clés et de générer un résumé automatique. Aujourd’hui, Xavier travaille sur l’automatisation de l’indexation de documents multimédia, à la fois en s’appuyant sur l’image et sur les contenus parlés.
Xavier Bost a d’ailleurs un parcours atypique. Âgé de 45 ans, notre homme a d’abord enseigné la philosophie pendant 15 ans dans le secondaire. “Un travail de DEA sur Platon en 2002 m’a donné l’occasion d’apprendre le grec ancien. Je me suis alors intéressé aux langues, plus particulièrement aux parentés entre langues, explique-t-il. Et comme il y a des méthodes assez algorithmiques qui sont utilisées dans ce domaine, la linguistique m’a conduit assez naturellement de la philosophie vers l’informatique”. Xavier a donc repris des études d’informatique, ce qui l’a amené à faire une thèse de doctorat au sein du LIA d’Avignon, un laboratoire en pointe sur le traitement automatique du langage et de la parole. Sujet de cette thèse : le résumé automatique de vidéos. L’idée étant de pouvoir soumettre une vidéo au logiciel, qu’il soit capable de repérer ses points forts et ses passages clés et de générer un résumé automatique. Aujourd’hui, Xavier travaille sur l’automatisation de l’indexation de documents multimédia, à la fois en s’appuyant sur l’image et sur les contenus parlés.
3 raisons pour internaliser sa R&D
Vous vous demandez peut-être quel est pour nous l’intérêt d’internaliser ce département innovation ? Cela fait sens pour trois sans raisons majeures :
- d’abord, parce que dans un logiciel de DAM, on collecte des données annotées (une vidéo transcrite, une image indexée, etc.) et que ces données sont précieuses pour nos algorithmes d’IA. Il est donc parfaitement naturel qu’un logiciel de DAM rencontre l’IA et le machine learning.
- ensuite, parce que cela nous permet d’être au plus près des besoins de nos utilisateurs qui ne peuvent pas être satisfaits avec les solutions et les catégories d’indexation grand public proposées par les outils des GAFAM. Pour répondre aux exigences de nos clients dans les secteurs de l’industrie, du tourisme ou du luxe, nous avons besoin de catégories beaucoup plus ciblées et de certaines spécificités.
- enfin, parce que la sécurité des données est primordiale et qu’il n’était pas question pour nous que les images et contenus de nos clients transitent vers des services déportés dont nous n’aurions pas la maîtrise. Leurs données sont donc conservées en interne. C’est une garantie que nous leur offrons.
Nos travaux en cours ?
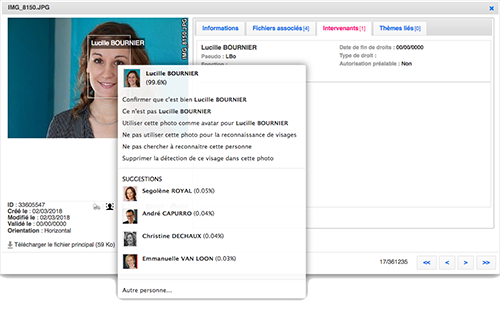
Un module de reconnaissance faciale complet. Comment ça marche ? C’est tout simple. L’utilisateur importe une photo, le logiciel détecte d’abord les visages et les associe à des personnes. “Cela suppose toutefois d’avoir auparavant nourri l’algorithme avec des images de ces personnes, explique Xavier. C’est un système auto-apprenant, mais pour que cela fonctionne et soit efficace, il faut le nourrir”. Ce système est d’autant plus intéressant qu’il permet de travailler à grande échelle, avec plusieurs centaines de personnes, et que le taux de réussite de cette reconnaissance faciale atteint 98%. Les clients qui seraient intéressées sont notamment les collectivités locales pour pouvoir identifier automatiquement les élus et les autres personnes présentes sur les clichés. Ce qui ferait gagner un temps précieux aux documentalistes. Car au bout de 3 ou 4 exemples, l’identification se fait automatiquement. “Cela peut aussi permettre de flouter les visages de quidam pour les vitrines publiques des sites de nos clients et ainsi respecter le droit à l’image” précise Xavier.
Transcription automatique de l’audio
Titouan Parcollet, lui, revient d’un séjour à Montréal, pôle international du deep learning. Il a travaillé là-bas dans l’équipe du pape de la discipline : Yoshua Bengio, chercheur canadien spécialiste en intelligence artificielle, et pionnier de l’apprentissage profond. L’homme planche, en effet, sur des systèmes qui nous intéressent beaucoup. Et Titouan a justement ramené dans ses valises une interface permettant d’intégrer directement l’entraînement des réseaux de neurones dans notre système actuel de transcription des contenus audio. Ce qui permettrait de profiter des meilleures technologies pour rendre notre logiciel Ajaris plus performant sur les contenus parlés et obtenir des transcriptions plus justes pour le français et pour l’anglais. “Tout cela devrait être prêt d’ici la fin de l’année” indique Xavier.
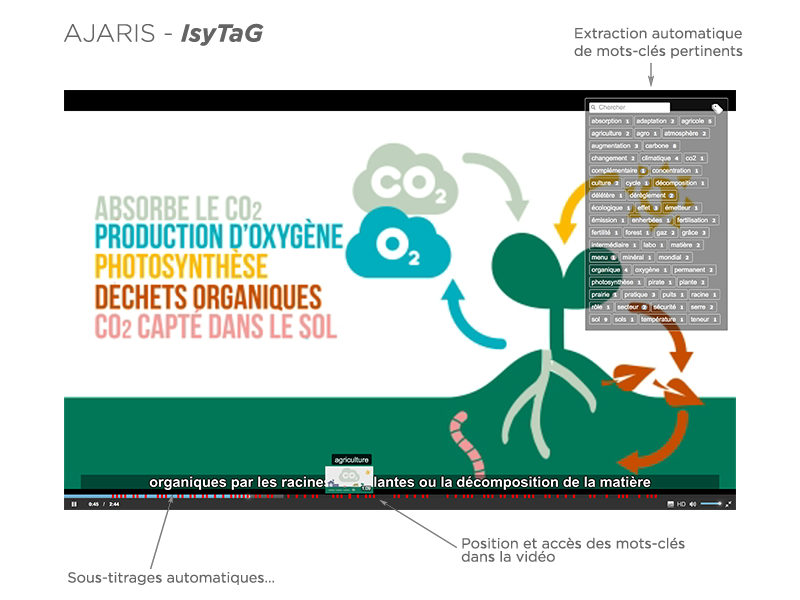
Pour quels usages ?
Cela pourrait être très utile pour le sous-titrage des vidéos, par exemple. Car, comme vous le savez, le sous-titrage est aujourd’hui devenu indispensable à la fois pour des questions d’accessibilité à tout type de public, mais aussi pour que les vidéos puissent être visionnées et comprises, même si l’utilisateur n’a pas la possibilité d’activer le son. “Une demande forte est en train d’émerger en ce sens” souligne Xavier. Mais la solution doit encore être perfectionnée, car dès que l’on commence à lui soumettre des échanges vocaux spontanés (où les personnes se coupent pas la parole, s’invectivent, parlent vite, etc.), la reconnaissance devient plus compliquée. La difficulté est la même pour des contenus thématiques spécifiques. Il est par ailleurs prévu que le logiciel intègre une interface de correction des sous-titres plus interactive et plus pratique que celle que nous proposons actuellement.
Enfin, la transcription vocale peut aussi être utilisée comme une source d’indexation. L’idée étant de repérer les mots et les concepts les plus fréquents, les thématiques pertinentes et que le logiciel comprenne de quoi il s’agit pour effectuer une indexation efficace et automatique.
Ce département R&D, c’est donc notre fierté, mais aussi et surtout le socle de notre logiciel et de tout ce qui nous permet d’envisager l’avenir avec l’assurance de profiter des meilleures technologies et d’être à jour dans ce domaine.
Vous avez des questions ? N’hésitez pas !
